AtomAlpaca
起因是我参加了前段时间的[https://www.bilibili.com/video/BV1NpdeYHETU/],入门了 RISC-V。然后突然有一天 mizu-bai 找到我发了一段聊天记录。
nihui:github.com/atomalpaca
nihui:这头像怎么和 mizu 这么像
小小跑:这头像怎么和 mizu 这么像然后我问这是什么群,mizu 姐姐说是 ncnn 的开发者群,给 ncnn 交个 pr 就能进,快来玩。
然后我看了一圈 issues,看了一圈代码,我说我不知道干什么啊,mizu 姐姐说有很多算子在 riscv 上没有优化你可以折腾一下。
首先我们需要一套 Riscv 的交叉编译工具链。riscv 给出的构建默认不包含 v 拓展,于是我们需要自己编译一份出来。
另外我们还需要支持 xtheadvector,这在 toolchain 中默认的 gcc 14 中是不支持的,所以我们要手动拉一份 gcc 15。
P.S. 写这篇文章的时候 gcc16 出来了,读者可以尝试一下()
git clone https://github.com/riscv-collab/riscv-gnu-toolchain
cd riscv-gnu-toolchain
git submodule update --init
rm -rf ./gcc
git clone https://gcc.gnu.org/git/gcc.git
cd gcc
git branch -r
git checkout releases/gcc-15
cd ..
mkdir build && cd build
# --prefix 指定的是工具链要放在的地方,注意要有写权限
# --with-arch 指定的是拓展,默认是 rv64gc
# 无需 make install,make 后会直接放到指定的目录
# 编译可能非常非常慢
../configure --prefix=/home/atal/riscv-toolchain/ --with-arch=rv64gcv --enable-multilib
make -j4为了方便我们可以把工具链的目录加到 PATH
变量里,这样就可以直接调用。
export PATH=$PATH:/home/atal/riscv-toolchain/binspike 是 riscv 自行开发的一个模拟器
首先编译 pk(proxy kernel)
git clone https://github.com/riscv/riscv-pk.git
cd riscv-pk
mkdir build && cd build
../configure --prefix=/home/atal/riscv-toolchain/ --host=riscv64-unknown-elf --with-arch=rv64gcv
make -j4
make install然后是 spike 本身
git clone https://github.com/riscv/riscv-isa-sim.git
cd riscv-isa-sim
mkdir build && cd build
../configure --prefix=/opt/riscv
make -j4
make install老版本的 spike 编译的时候需要加上
–with-isa=rv64gcv 来启用 v
拓展,但现在这个选项已经删掉了,现在我们只需要在运行的时候加上
–isa=rv64gcv 来指定运行时的架构。
使用方式是这样的:
riscv64-unknown-elf-gcc ./test.c -o test
spike --isa=rv64gcv pk ./test同时我们可以用 qemu
进行模拟,这两个选其中一个用就好。
git clone https://github.com/qemu/qemu
cd qemu
mkdir build && cd build
../configure --target-list=riscv64-softmmu,riscv64-linux-user --prefix=/home/atal/riscv-toolchain/qemu
make -j4
make installTODO,内容有点多可能会单独开一系列文章。
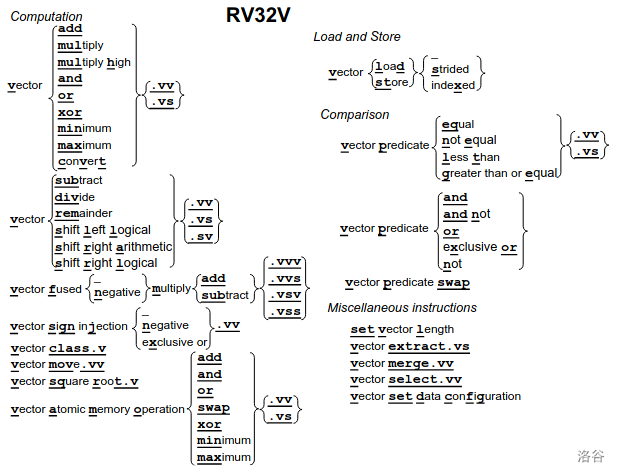
和 x86 选用的 SIMD 不同,Riscv
使用向量指令集来进行并行优化。
v 拓展新增了若干名称以 v
开头的“向量寄存器”(对 RV32V 来说,一般是
个),这些寄存器的长度由处理器分配的向量寄存器堆大小决定,处理器会把堆均匀地划分给各个启用的向量寄存器,并且把向量寄存器能够使用的最大长度存储在寄存器
mvl 中。能存储的元素数进一步由存储的元素长度决定。
我们可以选择性地启用或禁用部分向量寄存器,处理器会动态调整向量寄存器的长度。如假设我们有
字节的堆空间,并且启用全部
个 寄存器,每个寄存器都会分配到
字节的长度;如果我们仅启用其中两个,则每个寄存器都会变成
字节长,并且 mvl 将会随之动态变化。但 mvl
的值只能由处理器设置,软件层面无法直接修改 mvl 的值。
同时 v 拓展新增了
个非特权 CSR
寄存器:vstart,vxsat,vxrm,vcsr,vl,vtype,vlenb。
vxrm 和 vxsat 分别是 Vector Fixed-Point
Saturation Flag vxsat 和 Vector Fixed-Point Saturation Flag,他们都是
vcsr 中对应位的镜像。这些暂且掠过。
vl
设定了每次向量操作所操作的元素数量,我们只会操作从开头开始
vl 个元素,可以通过 setvl
指令设定。vstart
则进一步设置了向量操作会从哪一个元素开始进行操作(注意不会向后顺延),注意每次向量操作之后
vstart 都会被清零。
vlenb 是以字节为单位的向量寄存器长度。
vtype 中包含
vill,vma,vta,vsew
和 vlmul 五个字段。vsew
代表了每个元素的长度,vlmul 涉及到 v
拓展的另一个机制,多个向量寄存器可以进行拼接组合获取更长的向量,vlmul
则是寄存器拼接的数量。
vma 和 vta 分别指示了被 mask
的(之后会提到)元素和不在操作范围内的元素会被如何处理,分为“undisturbed”
和 “agnostic”。值为
代表 “undisturbed” 会全部保持原值,而 值为
代表 “agnostic” 既可能保持原值也可能全部写
。
我们使用 vld 从内存中读取连续的一段进入向量寄存器。如当
vsew 为
时,vld v0, 0(a0) 会从 a0 指向的地址开始,读取
a0,a0 + 4, a0 + 8... 直至 vl 设置的上限。
同时我们可以稀疏地读取数据,vlds v0, 0(a0), a1 会读取
a0, a0 + a1, a0 + 2a1 直至上限。或者将
存入另一向量寄存器,通过 vldx v0, a0, v1 读取。
存入内存只需将 vld 改为 vst。
操作的格式基本是
v + 操作名 + 操作种类后缀。操作分为向量与向量操作(.vv
后缀)和向量与标量(.vs 后缀)操作两种。
向量架构通过掩码(Mask)的方式来实现一些分支操作。RVV 拓展提供了
个向量谓词寄存器
vp{},我们可以将其视作一列
bool
值。我们可以在他们之间进行逻辑运算(vp{and, or, xor, etc.}),也可以将向量寄存器进行比较等操作的结果存入。我们在进行向量寄存器之间的操作时可以额外一共一个谓词寄存器,当谓词寄存器一个位置的值为
时这个位置不会进行操作,而是会根据 vma
位置的值来选择保持原值还是置
。
简单来说就是给编程语言提供了一个便于调用和管理的接口,让你不用在项目里写大量的内联汇编。
文档主要在 这,另外有个超好用的网站可以帮你快速搜索以及熟悉用途,向 Github 用户 dzaima 致敬。
Intrinsic
最方便的一点就是提供了类型系统,使得我们能像操作变量一样操作向量寄存器,而不是把自己训练成寄存器管理大师。
一个寄存器的大概格式为 v<type><vlmul>_t。
其中 type 可以取
int{8/16/32/64} | uint{8/16/32/64} | float{16/32/64} | bool{1/2/4/8/16/32/64},一看就知道什么意思!
vlmul 就是多少个寄存器拼在一起,大于一用
m{1/2/4/8} 来表示,小于的用 mf{2/4/8}
来表示拆成 2/4/8 份。注意 bool
类型不能拼,也不需要写 <vlmul> 这项,举个例子你应该写
vbool1_t。
另外你还可以在 <vlmul> 后面加个
x2/4/8 来构成元组类型,但是似乎没什么用。
指令的基本格式
__riscv_<instruction>_<operand>_<return_type>_<policy>。举个例子
vint32m1_t __riscv_vadd_vv_i32m1_m(vbool32_t vm, vint32m1_t vs2, vint32m1_t vs1, size_t vl);
instruction 就是指令名。operand
代表操作类型,如 vv。
这里的 return_type 采用简写,即
<i{8, 16, 32, 64} | u{8, 16, 32, 64} | f{16, 32, 64}><m{1, 2, 4, 8} | mf{2, 4, 8}>。
policy 用来表示 vta 和 vma
这两个寄存器,决定被 mask 和尾部的位置该怎么处理。
留空:不使用 mask,vta = 1
_tu:不使用 mask,vta = 0
_m 使用
mask,vta = 1,vma = 1
_tum 使用
mask,vta = 0,vma = 1
_mu 使用
mask,vta = 1,vma = 0
_tumu 使用
mask,vta = 0,vma = 0
Intrinsic 提供了 __riscv_vsetvl_*,将可用的
vl 和你提供的要计算的长度取
,确保得到的始终是合法的
vl。
我们先来讲讲怎么编译以及怎么跑测试。在 ncnn/toolchains
下有若干个针对不同平台进行设置的 cmake 文件,比如
riscv64-unknown-linux-gnu.toolchain.cmake。和 RISCV
有关的这几个基本只有选用的编译器不同。首先确保你设置里
RISCV_ROOT_PATH 这个环境变量。
export RISCV_ROOT_PATH=<path_to_your_riscv_toolchain>
mkdir build && cd build
cmake -DCMAKE_TOOLCHAIN_FILE=../toolchains/riscv64-unknown-linux-gnu.toolchain.cmake -DCMAKE_BUILD_TYPE=debug -DNCNN_COVERAGE=ON -DNCNN_RUNTIME_CPU=OFF -DNCNN_RVV=ON -DNCNN_ZFH=ON -DNCNN_ZVFH=ON -DNCNN_OPENMP=ON -DNCNN_BUILD_TOOLS=OFF -DNCNN_BUILD_EXAMPLES=OFF -DNCNN_BUILD_TESTS=ON ..
// 我们这里把 CMAKE_BUILD_TYPE 设置为 debug 是为了方便调试,如果要跑 benchmark 建议切换到 release
cmake --build . -j 8
TESTS_EXECUTABLE_LOADER=qemu-riscv64 TESTS_EXECUTABLE_LOADER_ARGUMENTS="-cpu;rv64,v=true,zfh=true,zvfh=true,vlen=256,elen=64,vext_spec=v1.0;-L;<path_to_your_riscv_toolchain>/sysroot" ctest --output-on-failure -j 8如果你想添加一个全新的算子你需要先阅读 这两篇文档,简而言之你要先实现一份
native 的版本并且在 CMakeList 里注册。
v, zfh, zvfh 和
xtheadvector 是 RISC-V 的四个拓展,简单介绍一下:
v:上面提到的向量拓展
zfh 半精度浮点数拓展,支持 16bit 的浮点数
zvfh 半精度浮点数的向量拓展
xtheadvector 其实就是 rvv-0.7.1
指令集,虽然已经被弃用但是作为曾经常用的标准,现在还有很多设备在用这套指令,于是给它塞到了
xthead 里。有 zfh 的功能和 v
拓展和 zvfh 的大部分功能。
也就是说 xtheadvector 不支持一些现在的 v
拓展的 Intrinsic。点击这里看更多。
各个厂商的各个设备都有可能随机地实现了其中几个拓展,因此我们编译的时候会把代码复制出好几份用不同的参数分别编译。
我们需要分别实现单精浮点数和半精浮点数的代码(layer_riscv.cpp
和
layer_riscv_zfh.cpp),前者会编译成rv64gc,rv64gcv,rv64gc_xtheadvector
三个版本,后者会编译成
rv64gc_zfh,rv64gcv_zfh_zvfh,rv64gc_zfh_xtheadvector。
你的代码需要同时支持这几种情况。我们需要通过
__riscv_vector、__riscv_xtheadvector 和
__riscv_zvfh
这几个宏来判断各个拓展是否开启,然后写出对应的正确代码。
首先我们在 src/layer/riscv 下,先建立
yourlayer_riscv.h。在 ncnn namesoace 里面新建一个
Yourlayer_riscv 继承自 native 版本的 Yourlayer
类。然后实现你要优化的函数。
例如
namespace ncnn {
class BNLL_riscv : public BNLL
{
public:
BNLL_riscv();
virtual int forward_inplace(Mat& bottom_top_blob, const Option& opt) const;
protected:
#if NCNN_ZFH
int forward_inplace_fp16s(Mat& bottom_top_blob, const Option& opt) const;
#endif
};
} // namespace ncnn 然后在 yourlayer_riscv.cpp 和
yourlayer_riscv_zfh.cpp 里分别实现 fp32 和 fp16
的版本:
namespace ncnn {
BNLL_riscv::BNLL_riscv()
{
#if __riscv_vector
support_packing = true;
#endif // __riscv_vector
#if NCNN_ZFH
#if __riscv_vector
support_fp16_storage = cpu_support_riscv_zvfh();
#else
support_fp16_storage = cpu_support_riscv_zfh();
#endif
#endif
}
int BNLL_riscv::forward_inplace(Mat& bottom_top_blob, const Option& opt) const
{
#if NCNN_ZFH
int elembits = bottom_top_blob.elembits();
if (opt.use_fp16_storage && elembits == 16)
{
return forward_inplace_fp16s(bottom_top_blob, opt);
}
#endif
int w = bottom_top_blob.w;
int h = bottom_top_blob.h;
int d = bottom_top_blob.d;
int channels = bottom_top_blob.c;
int elempack = bottom_top_blob.elempack;
int size = w * h * d * elempack;
#pragma omp parallel for num_threads(opt.num_threads)
for (int q = 0; q < channels; q++)
{
float* ptr = bottom_top_blob.channel(q);
#if __riscv_vector // 判断是否启用了 v 拓展
int n = size;
while (n > 0)
{
size_t vl = __riscv_vsetvl_e32m8(n);
vfloat32m8_t _p = __riscv_vle32_v_f32m8(ptr, vl);
vbool4_t _mask = __riscv_vmfgt_vf_f32m8_b4(_p, 0.f, vl);
#if __riscv_xtheadvector // 判断是否为 xtheadvector
vfloat32m8_t _comm = __riscv_vfsgnjx_vv_f32m8(_p, _p, vl);
_comm = __riscv_vfsgnjn_vv_f32m8(_comm, _comm, vl);
#else
vfloat32m8_t _comm = __riscv_vfsgnjn_vv_f32m8_mu(_mask, _p, _p, _p, vl); // 这条指令在 xtheadvector 里不存在
#endif
_comm = exp_ps(_comm, vl);
_comm = __riscv_vfadd_vf_f32m8(_comm, 1.f, vl);
_comm = log_ps(_comm, vl);
#if __riscv_xtheadvector // 判断是否为 xtheadvector
vfloat32m8_t _res = __riscv_vfadd_vv_f32m8(_comm, _p, vl);
_res = __riscv_vmerge_vvm_f32m8(_comm, _res, _mask, vl);
#else
vfloat32m8_t _res = __riscv_vfadd_vv_f32m8_mu(_mask, _comm, _comm, _p, vl); // 这条指令在 xtheadvector 里不存在
#endif
__riscv_vse32_v_f32m8(ptr, _res, vl);
ptr += vl;
n -= vl;
}
#else // __riscv_vector
// 标量版本
for (int i = 0; i < size; i++)
{
if (*ptr > 0)
*ptr = *ptr + logf(1.f + expf(-*ptr));
else
*ptr = logf(1.f + expf(*ptr));
++ptr;
}
#endif // __riscv_vector
}
return 0;
}
}然后我们需要测试这些代码是否在玄铁的各个设备上能够正常运行。为什么?因为用它的板子太多了。而且 ncnn ci 也测了(什么
首先我们要再下一份玄铁家的 toolchain 和 qeum。你可以从这里找到形如
Xuantie-900-gcc-linux-6.6.0-glibc-x86_64-V3.1.0-20250522.tar.gz
的东西和
Xuantie-qemu-x86_64-Ubuntu-20.04-V5.2.6-B20250415-1115.tar.gz
这种东西。你看到这里的时候可能会有更新的版本。
不知道为什么玄铁的工具链还要手机登录才能下载。好抽象。不懂哦。
然后你会在 ncnn/toolchains 下找到
{c906, c908, c910}-v310.toolchain.cmake
这种文件(你看到这里的时候可能会有更新的版本。)我们像刚刚一样进行编译和测试,但是这次要把
riscv-root-path 改成玄铁的路径。
export RISCV_ROOT_PATH=<your_xuantie_toolchain_path>
mkdir build && cd build
cmake -DCMAKE_TOOLCHAIN_FILE=../toolchains/c906-v301.toolchain.cmake -DCMAKE_BUILD_TYPE=release \
-DNCNN_OPENMP=OFF -DNCNN_THREADS=OFF \
-DNCNN_RUNTIME_CPU=OFF \
-DNCNN_RVV=OFF \
-DNCNN_XTHEADVECTOR=ON \
-DNCNN_ZFH=ON \
-DNCNN_ZVFH=OFF \
-DNCNN_SIMPLEOCV=ON -DNCNN_BUILD_EXAMPLES=ON -DNCNN_BUILD_TESTS=ON ..
cmake --build . -j 8
TESTS_EXECUTABLE_LOADER=<path_to_your_xuantie_qemu> TESTS_EXECUTABLE_LOADER_ARGUMENTS="-cpu;c906fdv" ctest --output-on-failure -j 8然后玄铁有一堆奇奇怪怪的上游 bug。点击即看。包括但不限于尾部不打扰不生效啊,fp16 和 fp32 互转会段错误啊。被创了很多次,无力吐槽了。